在我们打0xGame时,我们常常看到各种明显无实际意义的字符串,它们到底是什么呢?
什么是编码?
编码,是信息从一种形式或格式转换为另一种形式的过程,简单来讲就是语言的翻译过程。
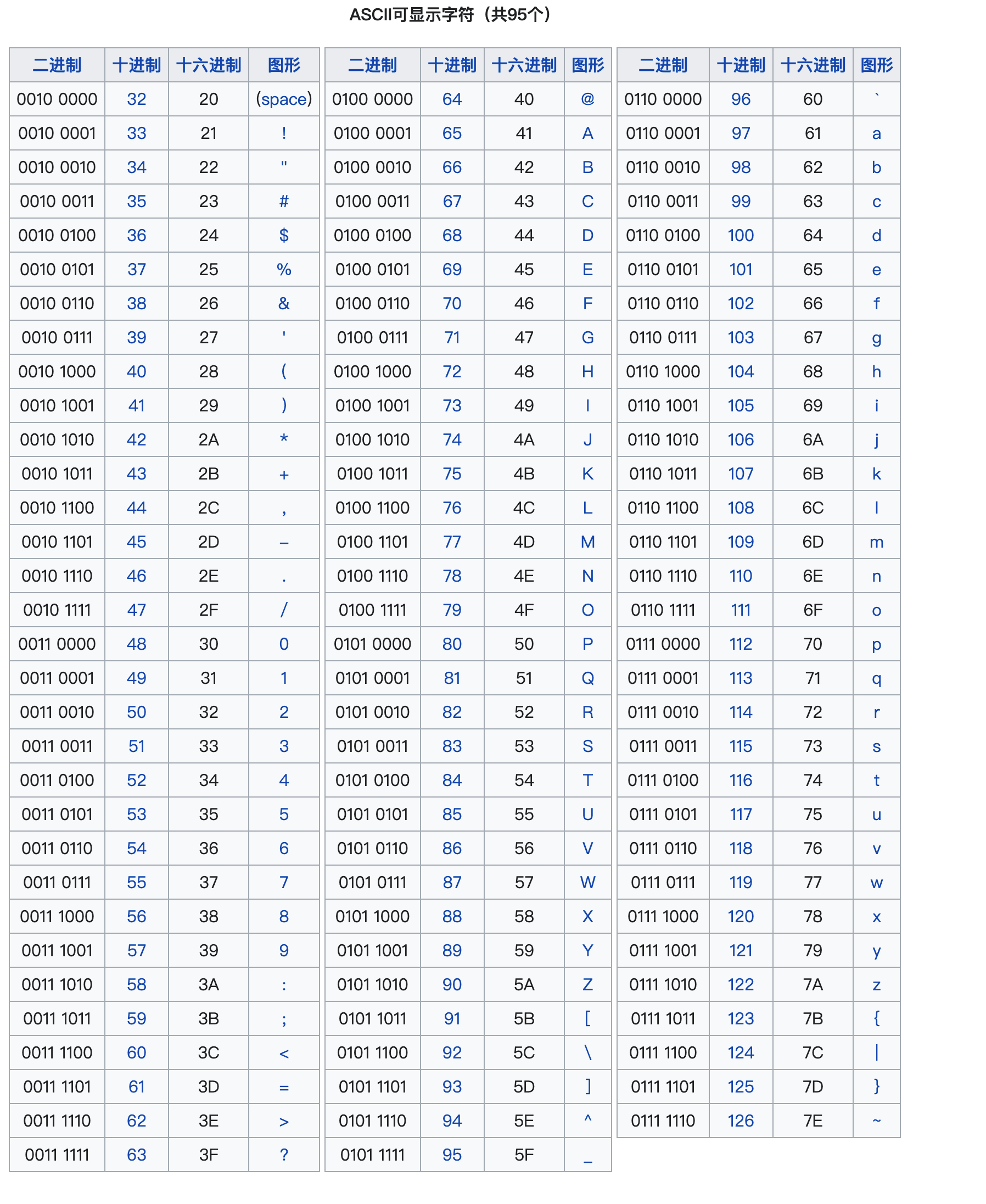
ASCII码
在计算机中,机器语言是由0和1组成的二进制数。而我们要想与计算机交流,就必须要将0和1组成的二进制序列转化,ASCII码便应运而生。
ASCII码是较早使用的一个编码集,它将字符或命令对应为十进制数字,再转化为机器可以阅读的二进制序列,构建了机器语言和自然语言的桥梁。这一过程便被称为“编码”(Encode or Encrypt)
在将我们的信息更换编辑器处理时,我们常常遇到乱码(“锟斤拷”等)的现象,原因就是编码不一样
除了ASCII码,常见的UTF-8,GBK等等也是二进制转字符的常见编码。每种编码之间互不相容,因此转换时容易造成“锟斤拷”的现象。
除了将二进制转换为字符的编码,为了安全传输数据,我们还有以下在字符串之间转换的编码类型
base家族
提到编码,首先想到的就是base家族~
Base64,就是包括小写字母a-z、大写字母A-Z、数字0-9、符号”+”、”/”一共64个字符的字符集
base64是常见的编码类型,常用于各类协议传输,简单数据混淆和存储
ctf比赛中大多以简单题型出现或和其他复杂题型同时考察,是值得注意的编码类型
- 原理:以最常见的“hello”举例,编码时,先将每个字符转换为对应的ASCII码(二进制):
字母 十进制数 二进制数
h -> 104 -> 01101000
e -> 101 -> 01100101
l -> 108 -> 01101100
l -> 108 -> 01101100
o -> 111 -> 01101111再将二进制连接,形成一个长的二进制流;
0110100001100101011011000110110001101111
将其按照六个一组重新分组,余位补0,再转为十进制
并查阅base64编码表,即ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
转化为对应的编码字符
011010 = 26 -> a
000110 = 6 -> G
010101 = 21 -> V
101100 = 44 -> s
011011 = 27 -> b
000110 = 6 -> G
111100 = 60 -> 8base64编码后编码字符数目必须是4的整数倍,为了补齐四的倍数位(即8位),最后一位补上0000000,编码为“=”
最终编码结果即为 aGVsbG8=
(是不是很神奇?)
注意到,因为base64以三个8位的二进制数作为一组,分为4个6位的二进制并转字符串,所以空余的数目不会大于2,即尾部的等号不会存在超过3个的情况。
因此base64的常见特征是:尾端带两个“==”(也可能是一个或者没有“=”)
同样的,base16,base32,base85等等也都是相似的操作,感兴趣的读者可以自行搜索了解
hex
HEX 是 十六进制(Hexadecimal)的简称,是一种以 16 为基数 的计数系统。它使用数字 0-9 和字母 A-F(或小写 a-f)来表示数值,其中字母部分对应十进制的 10-15。
hex直接转字符的情况比较少,但读者有必要熟悉,我们在以后的学习中还会遇到,这里不提前剧透
URL编码
URL编码是浏览器用于打包表单输入的编码格式,通过替换特殊字符确保数据可靠传输
URL 编码,也被称为百分号编码,是一种编码机制,用于将不安全或特殊的字符转换为
%后跟其 ASCII 的十六进制表示,以确保 URL 的安全传输。
ctf中可能会出现多次编码的情况,识别标志是百分号和后面的数字
Unicode编码
又称“统一码”,对所有字符均可识别和编码
通常用于绕过对特殊字符的过滤
#对于字符串"helloworld",Unicode编码有以下不同形式:
# 默认模式
\u0068\u0065\u006C\u006C\u006F\u0077\u006F\u0072\u006C\u0064
# 宽字符
\u{68}\u{65}\u{6C}\u{6C}\u{6F}\u{77}\u{6F}\u{72}\u{6C}\u{64}
# 编码模式
U+0068 U+0065 U+006C U+006C U+006F U+0077 U+006F U+0072 U+006C U+0064
# HTML 实体 十进制
helloworld
# CSS 实体 十六进制
\0068\0065\006C\006C\006F\0077\006F\0072\006C\0064摩尔斯电码
摩尔斯电码(Morse code)也被称作摩斯密码,是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号。
比如最近老乡鸡ctf的大众赛道就采取了这种编码方式

如图,两侧柱体的“长”“短”“空”代表着“—”“・”“ ”三种信号,组合后便可解码
编码内容的拓展
实际上,在广义的编码意义下,任何几个重复的字符都可以成为编码,因为它们的排列组合具有多样性,可以表示一个很大数量级的不同内容。
比如20250xGame week2出现的颜文字编码
实际上,这样的广义编码类型很多,我们需要开拓思维,识别其中的重复性内容,并恰当使用搜索引擎即可解出flag
关于解码
编码的逆过程被称为“解码”(Decode or Decrypt)
解码的方式参考base64的编码过程,逆向进行即可,这里不再赘述
需要注意的是:编码的过程是完全可逆的。不同于密码,编码的规则公开,且都是一一对应的关系,当我们知道编码信息和初始信息中的其一时,另一个的内容也已经明确。
原因呢,在于它和密码的目的不同:编码只是为了方便信息的传输,而密码是为了隐藏和保护信息。
一般地,我们在题目中只需要识别出编码类型,对于具体的解码,使用解码工具即可
当然也可以随波逐流,cyberchef或者ai一把梭
结语
本文中涉及的仅仅是常见编码,更多的内容还需读者自行探索
如果对文中的内容有疑问,欢迎找博主交流(,,・ω・,,)
喵喵喵
喵喵喵